项目介绍
”HelloBird”是一个基于微信小程序搭建的资源回收o2o平台,目的是为了实现废旧资源的流转。在”HelloBird”中,用户可以轻松的获取生活垃圾的基本信息,并能根据自己的实际情况便捷考虑是否将废品出售,在用户选择好要出售的废品并提交订单之后,系统将自动派送回收员上门服务,收取废品,使用户足不出户就能将生活中的垃圾得到妥善处理,还能获得一定的收益,并且实现了资源的再利用。
功能需求如下:
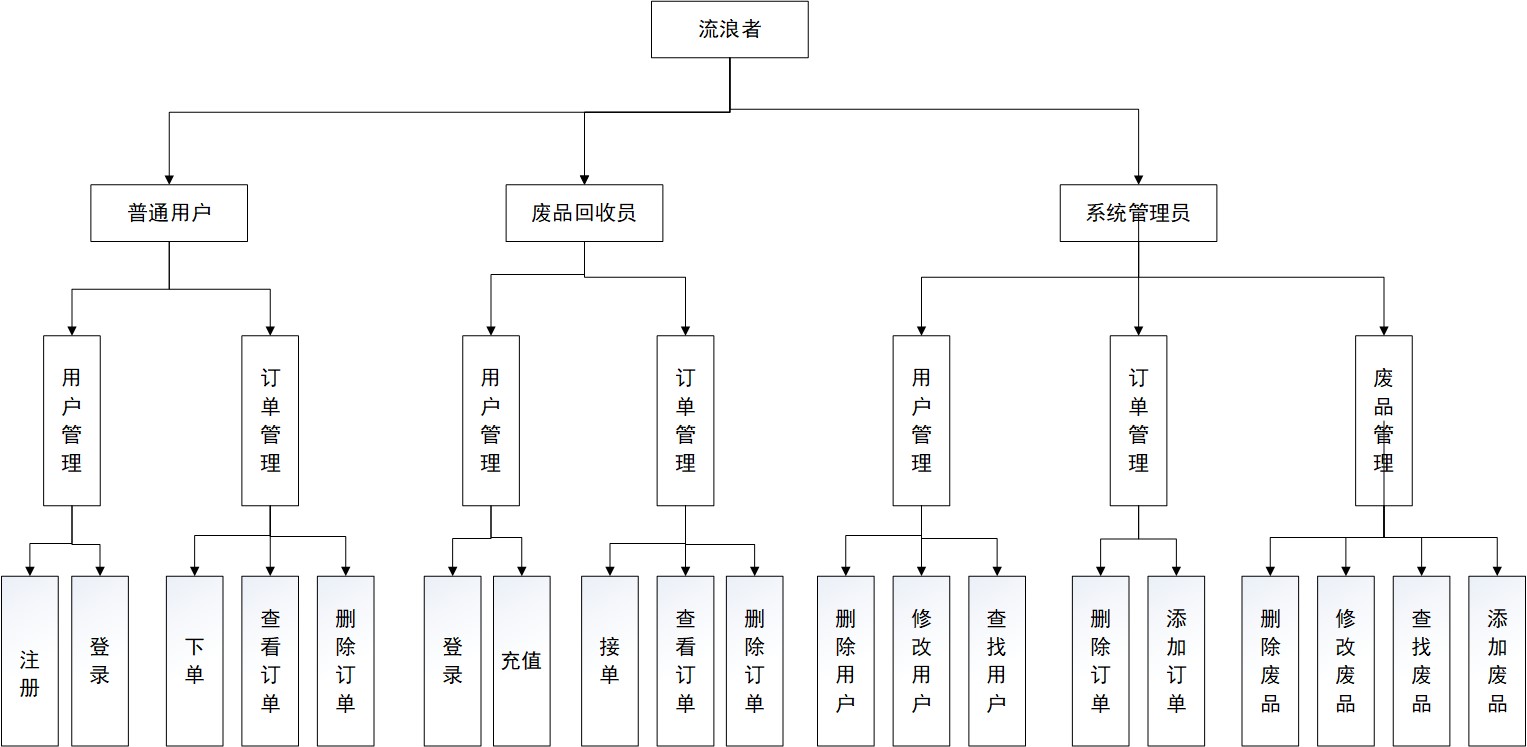
项目架构
”HelloBird”项目客户端采用微信web平台,使用JavaEE做后台架构,数据采用的是关系型数据库MySQL。在后台架构上,采用SSM(Spring+SpringMVC+Mybatis)框架,Mybatis负责持久层操作,SpringMVC作为前端控制器,处理前台和后台的交互,Spring作为IOC容器,为Mybatis和SpringMVC提供支持(事物操作等)。
架构图如下:

页面逻辑图如下: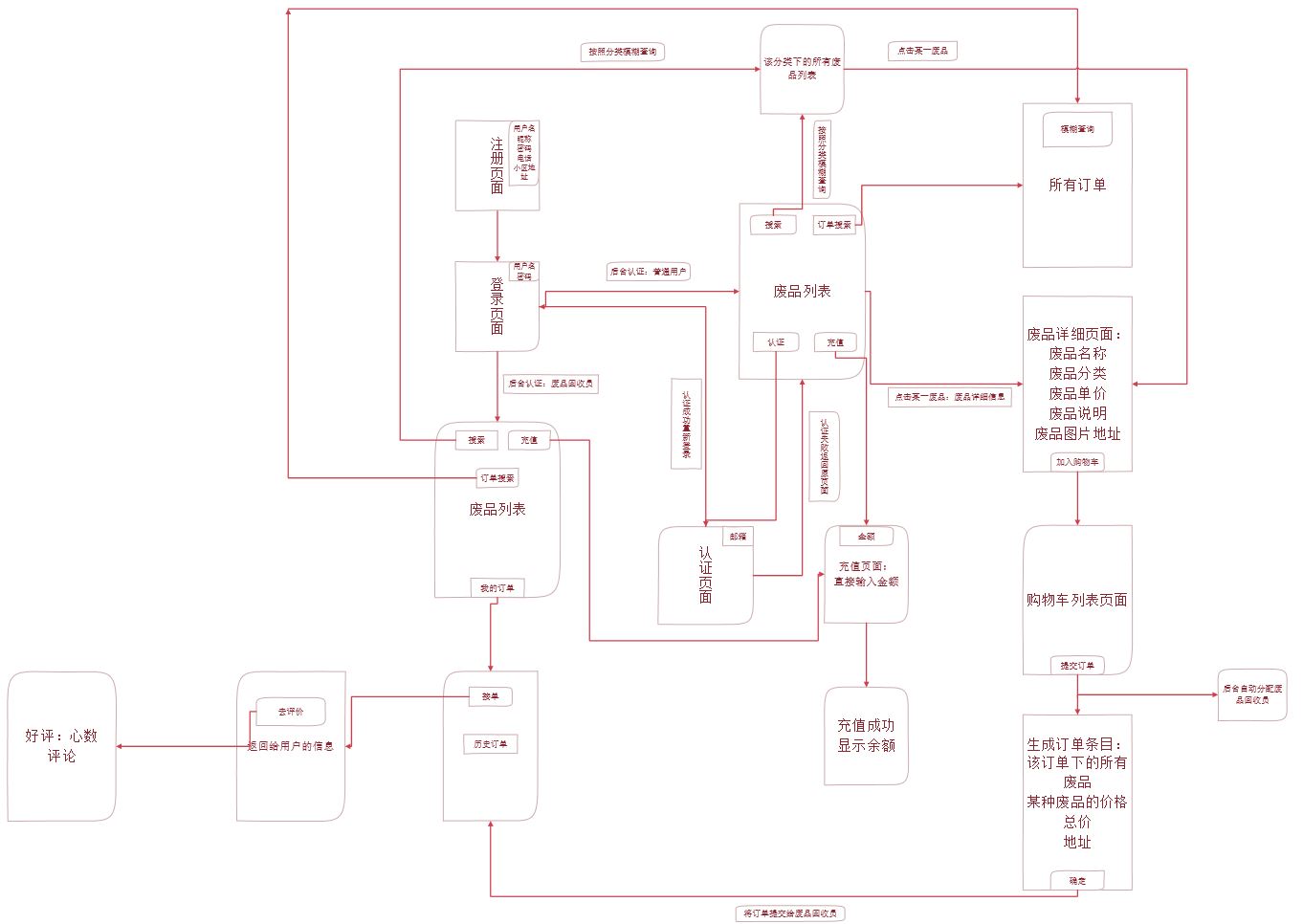
项目中遇到的问题
- 使用json进行前后台数据交互的格式: 该项目使用json作为前后台数据传输的格式,SpringMVC的两个注解非常友好的帮我进行封装于实现,封闭式@ResponseBody和@RequestBody,@ResponseBody负责将数据包装成json字符串返回给前台,@RequestBody则将从前台接收到的数据包装成对应的JavaBean对象。在使用过程中,出现了中文字符乱码问题,后来进行了解决。
1 | 1. 使用如下配置可解决字符乱码问题(全局设置): |
上面所讲的第二种方法中,关于produces(还有一个 consumes),可以查看此博客,做更深了解:
- Transfer-Encoding:chunked和Content-Disposition:inline;filename=f.txt问题: 在做项目的时候,响应头里面出现了 Transfer-Encoding:chunked和Content-Disposition:inline;filename=f.txt,让我百思不得其解,后来经过多方查阅,终于让我弄明白了到底是设么意思。
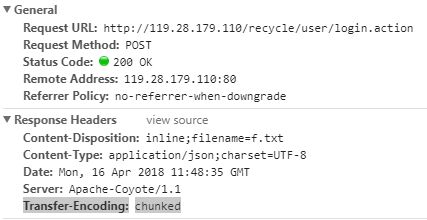
Transfer-Encoding:chunked 简单来说,Transfer-Encoding是一个Http的头部字段,意思是传输编码。而chunked是分块传输的意思,就是说对于输出内容长度不确定的,如gzip格式等,就会用到分块传输技术。参考博客:
Content-Disposition:inline;filename=f.txt 初遇这个响应头的时候我也是有点懵,不知道什么意思,后来也搞明白了。该属性设置的是在文件下载时对下载文件的一个标识字段。参考链接:
- session问题和token的使用: 该项目是基于微信小程序的,在保存用户登录状态和身份验证这一点上,我首先想到了用session,同时我想项目比较小,可以把用户的购物车放在session中,一次会话结束就将session里面的购物车清除,后来我发现了这其中的问题。首先:微信小程序不支持Cookie(意味着session也用不了),这在项目后期对于我的打击肯定是很大的,因为我的好多业务逻辑都是基于session的,session用不了那么项目就瘫痪了一大半,后来经过冷静思考也发现的我设计的问题,关于session的问题只是其次,用户的购物车放在session中,一次会话后就被清除,这显然是不合理的,对于用户的信息,我们需要把它固话在数据库中,后来我又重新增添一张表来保存用户的购物车,这个逻辑想明白之后,还有一点不知道怎么弄,session用不了,那用什么好呢?后来我想到了使用token。
- token是什么:token是一个加密的字符串,里面包含了后台给前台传递的加密信息(不容易被破解)
一点总结——我的心里话
说实话,自己真正做完一个项目确实挺开心,特别是在把每一个接口都测试好,并且项目真正跑起来的时候,感觉身体特别放松,觉得付出的一切都值得。作为项目负责人,需要考虑的事情特别多,一边需要和团队成员沟通,讨论需求,讨论接口,另一边还需要思考如何进行后台的整个架构,还要关心项目的进度等等,虽然团队在磨合过程中确实出现了很多问题,比如由于前期的交流不充分,需求讨论的不清楚,导致后面的接口改了好多次。还有比如原先对微信小程序的机制不是太了解,差点导致项目崩盘等等。但好在我们都坚持了下来,不管这个项目做得好不好,但我们起码还是把它完成了,总的来说还是要谢谢我们的团队,谢谢这次做项目的经历,让我得到了锻炼与成长,同时也让我明白了作为一个项目负责人,应该明白如何和组员进行良好的沟通,应该有一个清晰的项目进度计划,应该制定一个完善的奖惩措施,应该统筹安排好每个分支的工作。确实,一次历练就是一次成长,一次成长对于整个人生来说弥足珍贵!